Visual Prompting via Image Inpainting
Supplementary Material
- 8. Comaprison of the segmentation results for different models
- 9. Segmentation results (all results for split 0 of pascal 5i)
- 10. Colorization results
- 11. Detection results
- 12. Other results
- 13. Support examples effect
- 14. Failure cases
- 15. Synthetic data results
- 16. Examples from dataset
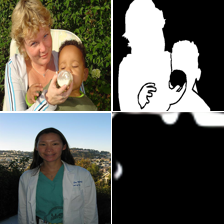
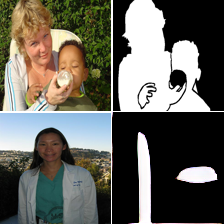
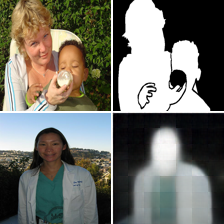
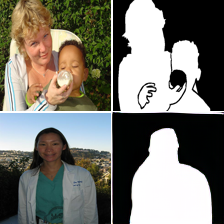
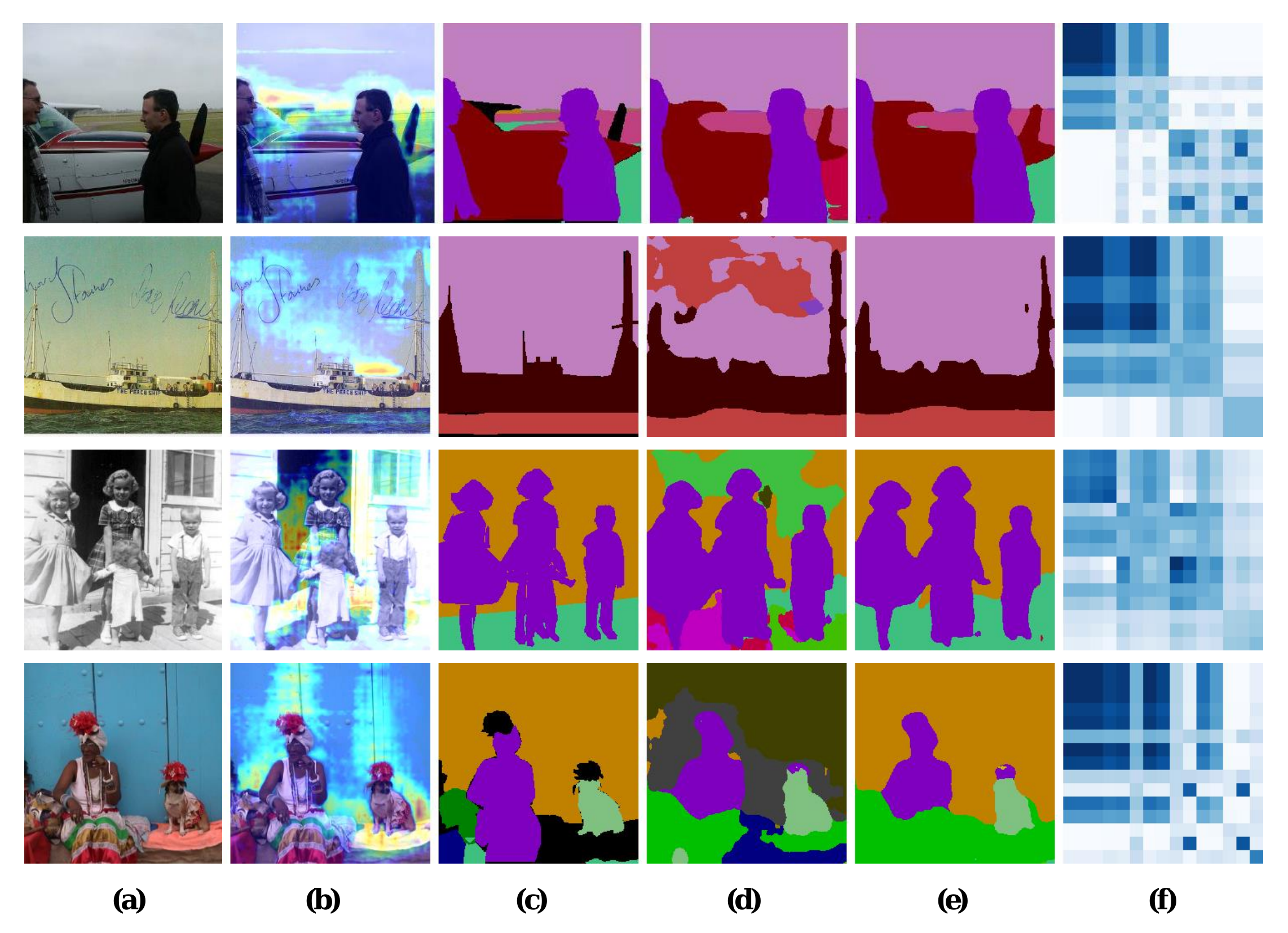
8. Comaprison of the segmentation results for different models
We provide here the segmentation results for the 4 models we used in the paper: BEIT [1], VQGAN [15], MAE[20] and our MAE+VQGAN.
The in-painted area is the bottom-right square in each grid-image.
| BEIT | VQGAN | MAE | MAE+VQGAN |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
9. Segmentation results (all results for split 0 of pascal 5i)
We provide here the segmentation results for our MAE+VQGAN model on the full split 0 of pascal 5i [44].
The in-painted area is the bottom-right square in each grid-image.
10. Colorization results
We provide here colorization results for our MAE+VQGAN model.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
11. Detection results
We provide here the detection results for our MAE+VQGAN model, after the post-processing that was described in the paper on the in-painted bottom-right square in each grid-image.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
12. Other results
We provide here more results of our MAE+VQGAN model. As discussed in the paper, the task is defined solely by the given support examples.
The in-painted area is the bottom-right square in each grid-image.
Please hover over the images to see the inpainting result.

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
13. Failure cases
We provide here failure cases of our MAE+VQGAN model.
The in-painted area is the bottom-right square in each grid-image.
Please hover over the images to see the inpainting result.
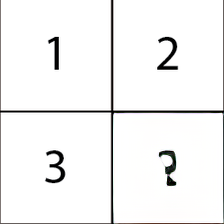
|

|

|

|

|

|

|

|
14. Support Examples Effect
Each row includes the same query image, with different support examples.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
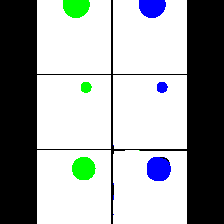
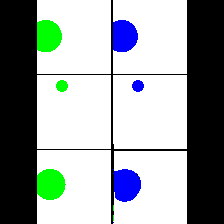
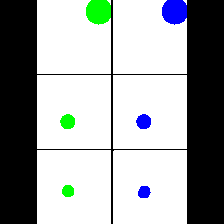
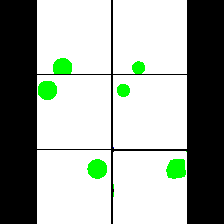
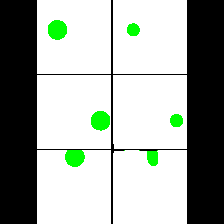
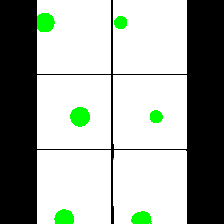
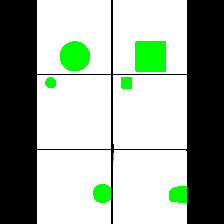
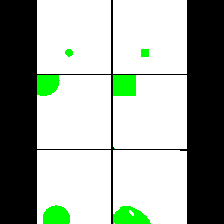
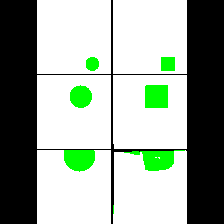
15. Synthetic Data
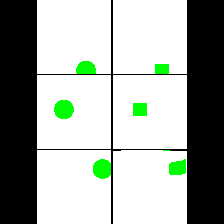
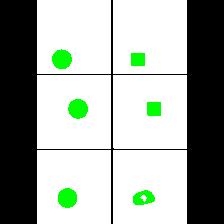
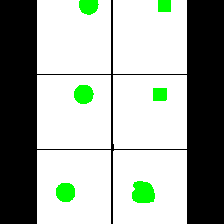
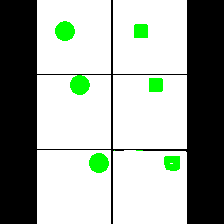
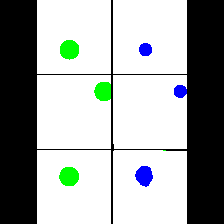
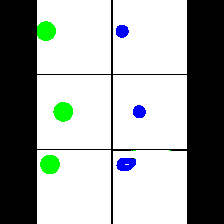
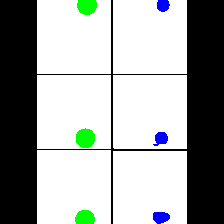
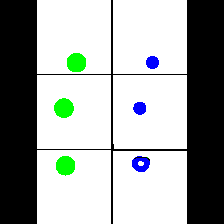
We provide here the results of our MAE+VQGAN model on the 6 synthetic tasks we created.
The in-painted area is the bottom-right square in each grid-image.
Color
 |
 |
 |
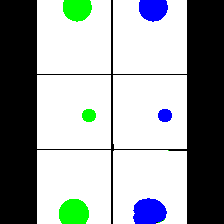 |
Size
 |
 |
 |
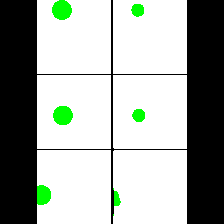 |
Shape
 |
 |
 |
 |
Size & Shape
 |
 |
 |
 |
Shape & Color
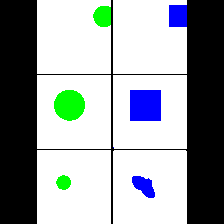 |
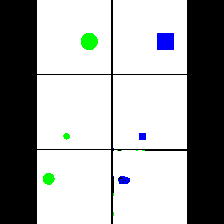 |
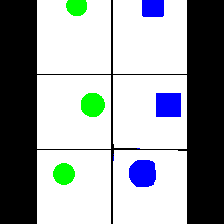 |
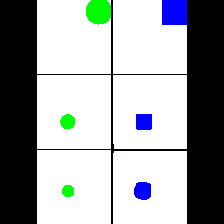 |
Size & Color
 |
 |
 |
 |
16. Examples from dataset
Please click on the images to see in full size.
Multiple Images
| Bounding box | Saliency | No annotations |
|---|---|---|
 |
 |
 |
| Mask | Pose | Uncategorized |
 |
 |
 |
Single Images
| Bounding box | Architecture | No annotations | Uncategorized |
|---|---|---|---|
 |
 |
 |
 |