Mining the Common Units in a Model Zoo
* Equal contribution
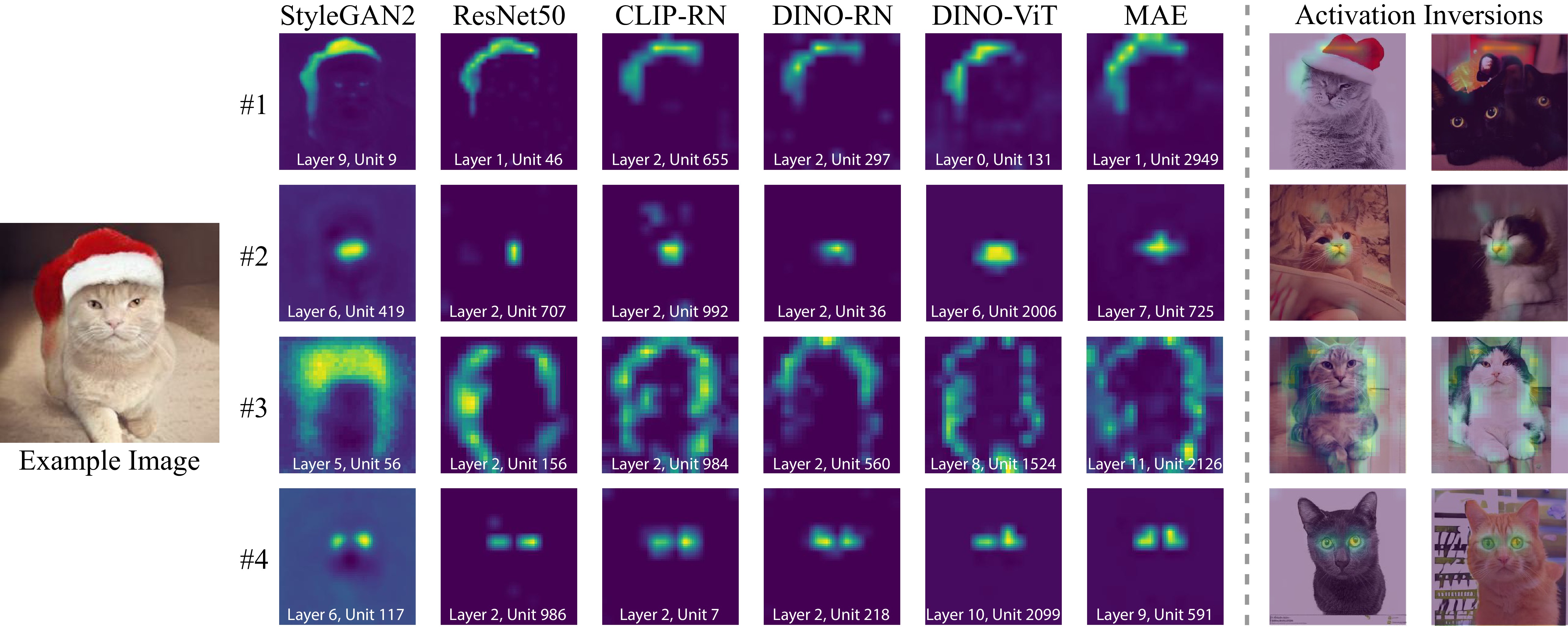
Mining for "Rosetta Neurons". Our findings demonstrate the existence of matching neurons across different models that express a shared concept (such as object contours, object parts, and colors). These concepts emerge without any supervision or manual annotations. We visualize the concepts with heatmaps and a novel inversion technique (two right columns).
Do different neural networks, trained for various vision tasks, share some common representations? In this paper, we demonstrate the existence of common features we call "Rosetta Neurons" across a range of models with different architectures, different tasks (generative and discriminative), and different types of supervision (class-supervised, text-supervised, self-supervised). We present an algorithm for mining a dictionary of Rosetta Neurons across several popular vision models: Class Supervised-ResNet50, DINO-ResNet50, DINO-ViT, MAE, CLIP-ResNet50, BigGAN, StyleGAN-2, StyleGAN-XL. Our findings suggest that certain visual concepts and structures are inherently embedded in the natural world and can be learned by different models regardless of the specific task or architecture, and without the use of semantic labels. We can visualize shared concepts directly due to generative models included in our analysis. The Rosetta Neurons facilitate model-to-model translation enabling various inversion-based manipulations, including cross-class alignments, shifting, zooming, and more, without the need for specialized training.
Rosetta Neurons guided image inversion
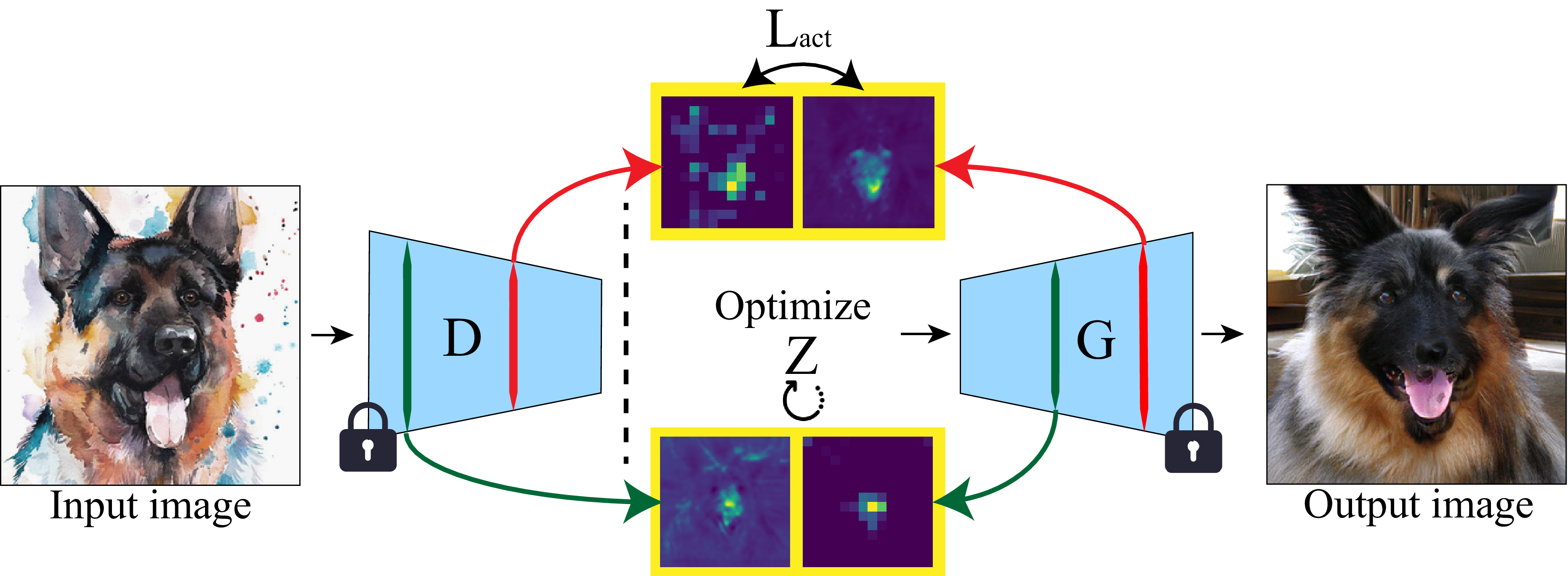
An input image is passed through a discriminative model D (i.e.: DINO) to obtain the Rosetta Neurons’ activation maps. Then, the latent code Z of the generator is optimized to match those activation maps, according to the extracted pairs.
By incorporating the Rosetta Neurons in the image inversion process, we can invert sketches and cartoons (first row), and generate similar in-distribution images (last row):

A subset of the Rosetta Neurons from the input images that were matched during the inversion process is shown in the middle rows.
Rosetta Neurons guided editing
Direct manipulations on the activation maps corresponding to the Rosetta neurons are translated to manipulations in the image space. We use two models (top row - StyleGAN2, bottom two rows - BigGAN) and utilize the matches between each of them to DINO-RN:

Acknowledgements
The authors would like to thank Niv Haim, Bill Peebles, Sasha Sax, Karttikeya Mangalam and Xinlei Chen for the helpful discussions. YG is funded by the Berkeley Fellowship. AS gratefully acknowledges financial support for this publication by the Fulbright U.S. Postdoctoral Program, which is sponsored by the U.S. Department of State. Its contents are solely the responsibility of the author and do not necessarily represent the official views of the Fulbright Program or the Government of the United States. Additional funding came from DARPA MCS and ONR MURI.