of Neurons in CLIP
ICLR 2025
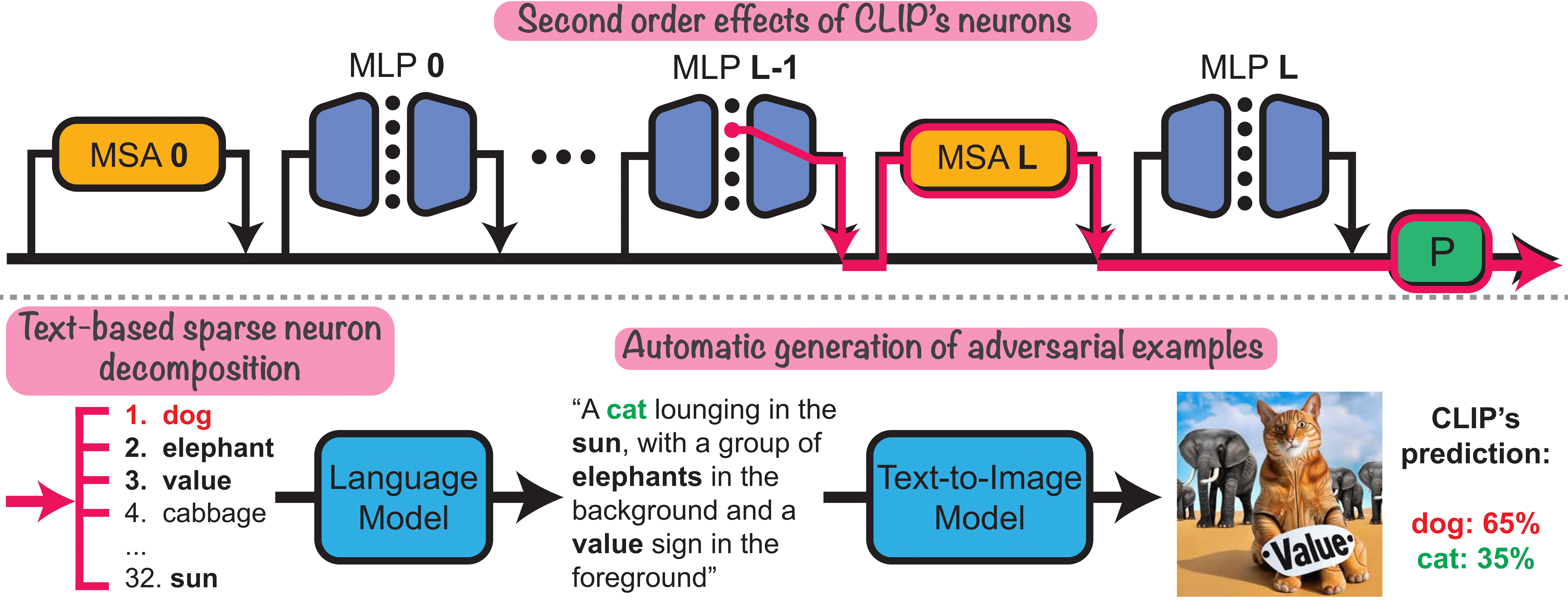
Second order effects of CLIP's neurons. Top: We analyze the second-order effects of neurons in CLIP-ViT (flow in pink). Bottom-left: Each second-order effect of a neuron can be decomposed to a sparse set of word directions in the joint text-image space. Bottom-right: co-appearing words in these sets can be used for mass-generation of semantic adversarial images.
We interpret the function of individual neurons in CLIP by automatically describing them using text. Analyzing the direct effects (i.e. the flow from a neuron through the residual stream to the output) or the indirect effects (overall contribution) fails to capture the neurons' function in CLIP. Therefore, we present the "second-order lens", analyzing the effect flowing from a neuron through the later attention heads, directly to the output. We find that these effects are highly selective: for each neuron, the effect is significant for <2% of the images. Moreover, each effect can be approximated by a single direction in the text-image space of CLIP. We describe neurons by decomposing these directions into sparse sets of text representations. The sets reveal polysemantic behavior - each neuron corresponds to multiple, often unrelated, concepts (e.g. ships and cars). Exploiting this neuron polysemy, we mass-produce "semantic" adversarial examples by generating images with concepts spuriously correlated to the incorrect class. Additionally, we use the second-order effects for zero-shot segmentation and attribute discovery in images. Our results indicate that a scalable understanding of neurons can be used for model deception and for introducing new model capabilities.
Second-order effects of neuronsOur goal is to interpret individual neurons in CLIP-ViT - post-GELU single channel activations in the MLPs. These neurons have different types of contributions to the output — the first-order (direct) effects, second-order effects, and (higher-order) indirect effects:
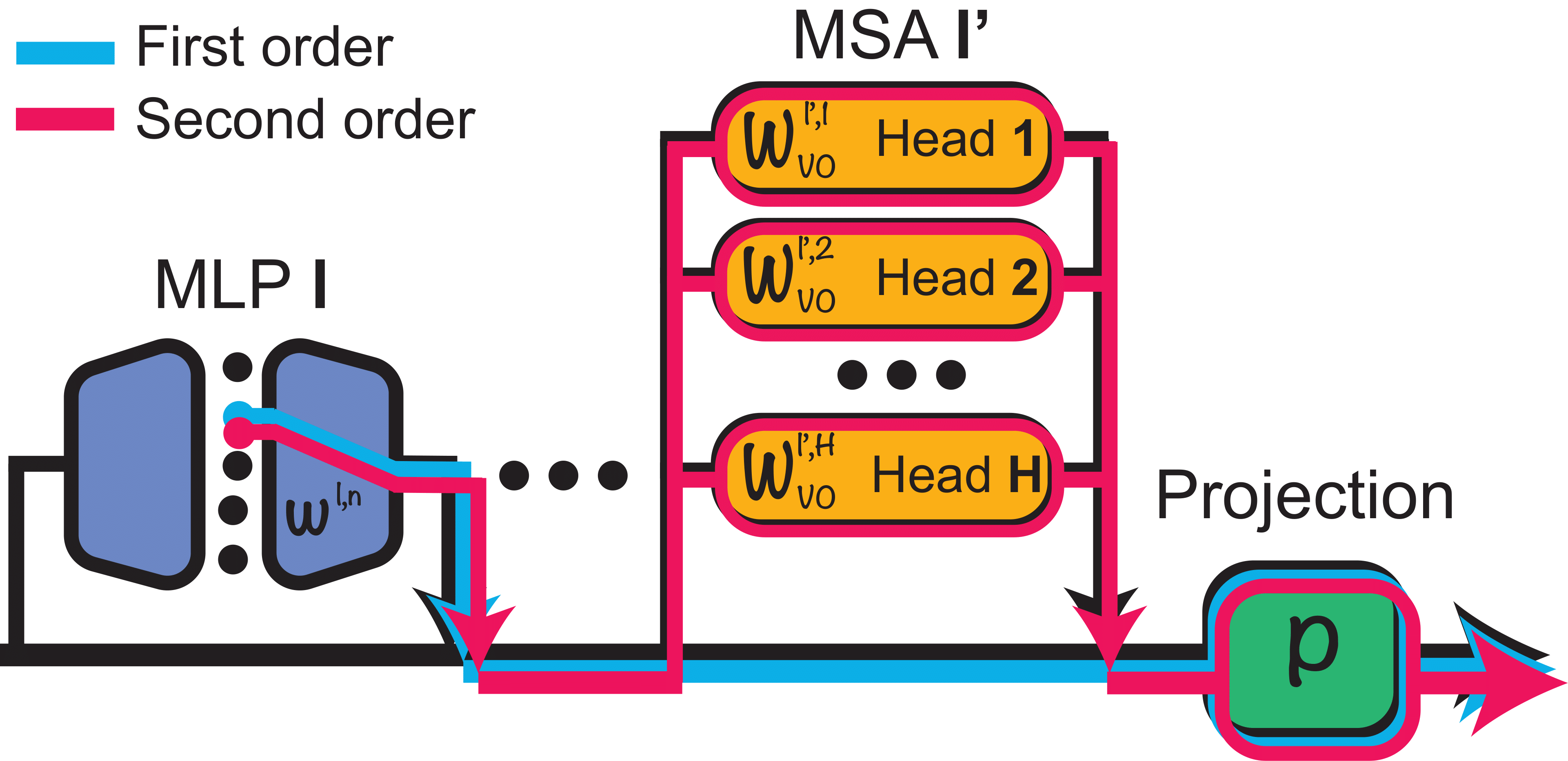
As shown in our previous work, the first-order (direct) effect of neurons - the flow from a neuron, through the residual stream directly to the output - is negligible.
Moreover, analyzing the indirect effects of neurons by ablating each one of them individually and measuring the change in output, does not reveal much: Most information is stored redundantly with many neurons encoding the same concept.
To address this, we introduce a "second-order lens" for investigating the second-order effect of a neuron - its total contribution to the output, flowing via all the consecutive attention heads.
Characterizing the second-order effects
Analyzing the empirical behavior of the second-order effects, computed for images in ImageNet, we find that:
- Only neurons from the late MLP layers have a significant second-order effect.
- Second-order effects are highly selective: Each individual neuron has a significant effect for less than 2% of the images.
- For each neuron $n$, its effect can be approximated by one linear direction in the output space $r_n \in {R}^d$. The second order effect of $n$ for an image $I$ is $\alpha_n(I)r_n + c_{bias}$, where $\alpha(I) \in R$ is an image-dependant coefficient, and $c_{bias}$ is a per-neuron constant bias term.
Sparse decomposition of neurons
Since $r_n$ lies in a shared image-text space, we can decompose it to a sparse set of text directions. We use a sparse coding method (Orthogonal Matching Pursuit) to mine for a small set of texts for each neuron, out of a large pool of descriptions. We apply the method for two types of initial text pools - the most common words in English, and LLM-generated image descriptions:
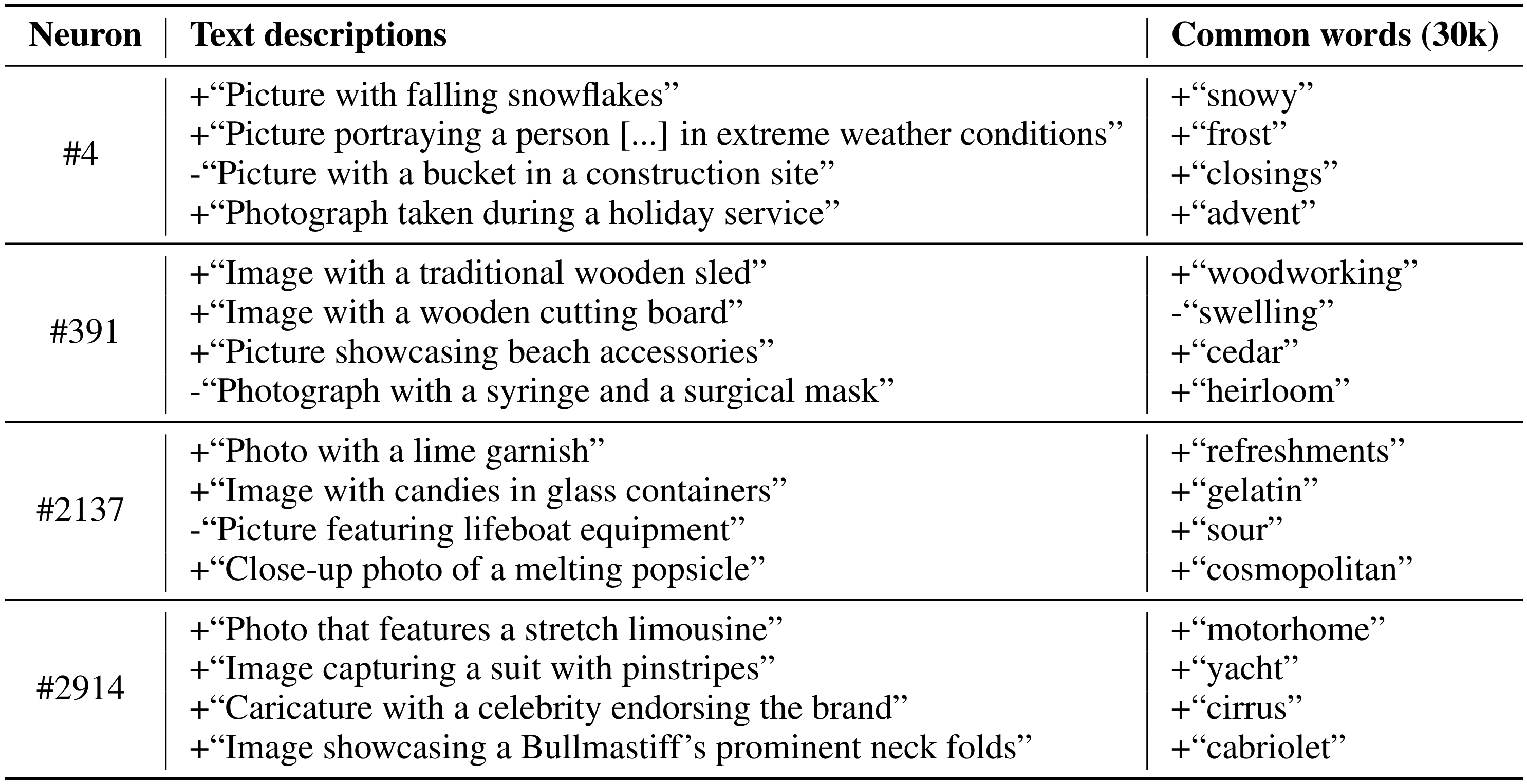
These text representations show that neurons are polysemantic - each neuron corresponds to multiple semantic concepts (e.g. writing both toward "yacht" and a type of a car - "cabriolet").
To verify that the neuron decompositions are meaningful, we show that these concepts correctly track which inputs activate a given neuron:

Automatic generation of adversarial examples
The sparse decomposition of $r_n$'s allows us to find overlapping concepts that neurons are writing to. We use these spurious cues to generate "semantic" adversarial images.
Our pipeline, uses the sparse decompositions to mine for spurious concepts (words) that correlate with the incorrect class in CLIP (e.g. "elephant", that correlates with "dog"). The next step in the pipeline combines these words into image descriptions that include the correct class name ("cat") and generates adversarial images by providing these descriptions to a text-to-image model.
We apply this technique to automatically produce adversarial images for a variety of classification tasks:

Our quantitative analysis in the paper shows that incorporating spuriously overlapping concepts in an image deceives CLIP with a significant success rate (see the paper for more details).
Concept discovery in images We automatically discover the image concepts by aggregating words that correspond to the neurons that are activated on the image. We start from the set of activated neurons (for which $\alpha(I)$ is above the 98th percentile of norms computed across ImageNet images) and merge the scores of the words in the decomposition of these neurons.
The top words extracted from these neurons relate semantically to the objects in the image and their locations:

Zero-shot segmentation
Each neuron corresponds to an attribution map, by looking at its spatial activations on each image patch. Ensembling the neurons that contribute towards a concept results in an aggregated attribution map:

Binarizing these attribution maps yields a strong zero-shot image segmenter that outperforms recent work (see the paper for more details).
Acknowledgments
We would like to thank Alexander Pan for helpful feedback on the manuscript. YG is supported by the Google Fellowship. AE is supported in part by DoD, including DARPA's MCS and ONR MURI, as well as funding from SAP. JS is supported by the NSF Awards No. 1804794 & 2031899.